Citus 分布式 PostgreSQL 集群 – SQL Reference(查询分布式表 SQL)
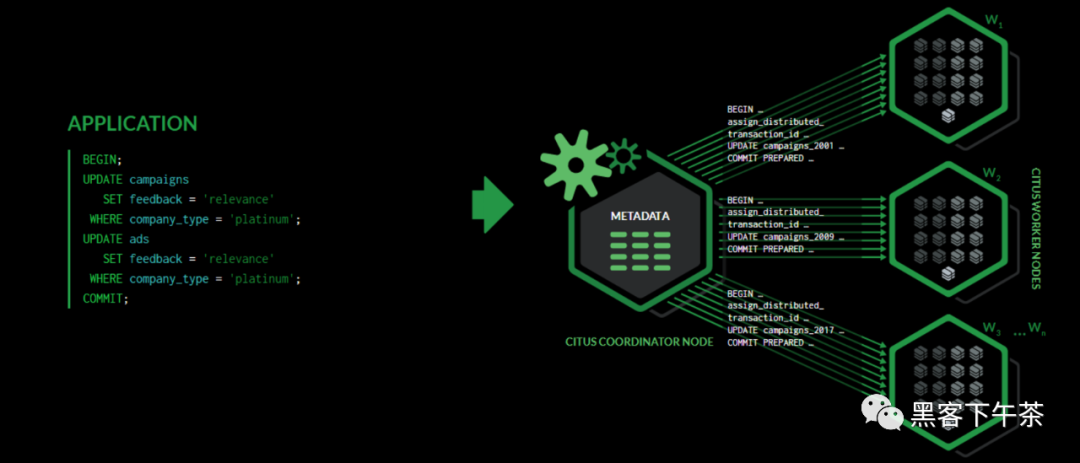
如前几节所述,Citus 是一个扩展,它扩展了最新的PostgreSQL 以进行分布式执行。这意味着您可以在Citus 协调器上使用标准 PostgreSQLSELECT 查询进行查询。Citus 将并行化涉及复杂选择、分组和排序以及JOIN 的SELECT 查询,以加快查询性能。在高层次上,Citus 将SELECT 查询划分为更小的查询片段,将这些查询片段分配给worker,监督他们的执行,合并他们的结果(如果需要,对它们进行排序),并将最终结果返回给用户。
- SELECT
- http://www.postgresql.org/docs/current/static/sql-select.html
在以下部分中,我们将讨论您可以使用Citus 运行的不同类型的查询。
聚合函数
Citus 支持和并行化PostgreSQL 支持的大多数聚合函数,包括自定义用户定义的聚合。 聚合使用以下三种方法之一执行,优先顺序如下:
-
当聚合按表的分布列分组时,
Citus可以将整个查询的执行下推到每个worker。 在这种情况下支持所有聚合,并在worker上并行执行。(任何正在使用的自定义聚合都必须安装在worker身上。) -
当聚合没有按表的分布列分组时,
Citus仍然可以根据具体情况进行优化。Citus对sum()、avg()和count(distinct)等某些聚合有内部规则,允许它重写查询以对worker进行部分聚合。例如,为了计算平均值,Citus从每个worker那里获得一个总和和一个计数,然后coordinator节点计算最终的平均值。特殊情况聚合的完整列表:avg, min, max, sum, count, array_agg, jsonb_agg, jsonb_object_agg, json_agg, json_object_agg, bit_and, bit_or, bool_and, bool_or, every, hll_add_agg, hll_union_agg, topn_add_agg, topn_union_agg, any_value, var_pop(float4), var_pop(float8), var_samp(float4), var_samp(float8), variance(float4), variance(float8) stddev_pop(float4), stddev_pop(float8), stddev_samp(float4), stddev_samp(float8) stddev(float4), stddev(float8) tdigest(double precision, int), tdigest_percentile(double precision, int, double precision), tdigest_percentile(double precision, int, double precision[]), tdigest_percentile(tdigest, double precision), tdigest_percentile(tdigest, double precision[]), tdigest_percentile_of(double precision, int, double precision), tdigest_percentile_of(double precision, int, double precision[]), tdigest_percentile_of(tdigest, double precision), tdigest_percentile_of(tdigest, double precision[])
-
最后的手段:从
worker中提取所有行并在coordinator节点上执行聚合。 如果聚合未在分布列上分组,并且不是预定义的特殊情况之一,则Citus会退回到这种方法。 它会导致网络开销,并且如果要聚合的数据集太大,可能会耗尽coordinator的资源。(可以禁用此回退,见下文。)
请注意,查询中的微小更改可能会改变执行模式,从而导致潜在的令人惊讶的低效率。例如,按非分布列分组的sum(x) 可以使用分布式执行,而sum(distinct x) 必须将整个输入记录集拉到coordinator。
SELECT sum(value1), sum(distinct value2) FROM distributed_table;为避免意外将数据拉到coordinator,可以设置一个GUC:
SET citus.coordinator_aggregation_strategy TO 'disabled';请注意,禁用coordinator 聚合策略将完全阻止“类型三”(最后的手段) 聚合查询工作。
Count (Distinct) 聚合
Citus 以多种方式支持count(distinct) 聚合。
如果count(distinct) 聚合在分布列上,Citus 可以直接将查询下推给worker。
如果不是,Citus 对每个worker 运行select distinct 语句,
并将列表返回给coordinator,从中获取最终计数。
请注意,当worker 拥有更多distinct 项时,传输此数据会变得更慢。
对于包含多个count(distinct) 聚合的查询尤其如此,例如:
-- multiple distinct counts in one query tend to be slow SELECT count(distinct a), count(distinct b), count(distinct c) FROM table_abc;对于这类查询,worker 上产生的select distinct 语句本质上会产生要传输到coordinator 的行的cross-product(叉积)。
为了提高性能,您可以选择进行近似计数。请按照以下步骤操作:
- 在所有
PostgreSQL实例(coordinator和所有worker)上下载并安装hll扩展。有关获取扩展的详细信息,请访问PostgreSQL hll github 存储库。- https://github.com/citusdata/postgresql-hll
- 只需从
coordinator运行以下命令,即可在所有PostgreSQL实例上创建hll扩展CREATE EXTENSION hll; - 通过设置
Citus.count_distinct_error_rate配置值启用计数不同的近似值。 此配置设置的较低值预计会提供更准确的结果,但需要更多时间进行计算。我们建议将其设置为0.005。SET citus.count_distinct_error_rate to 0.005;在这一步之后,
count(distinct)聚合会自动切换到使用HLL,而无需对您的查询进行任何更改。 您应该能够在表的任何列上运行近似count distinct查询。
HyperLogLog 列
某些用户已经将他们的数据存储为HLL 列。在这种情况下,他们可以通过调用hll_union_agg(hll_column) 动态汇总这些数据。
估计 Top N 个项
通过应用count、sort 和limit 来计算集合中的前n 个元素很简单。 然而,随着数据大小的增加,这种方法变得缓慢且资源密集。使用近似值更有效。
Postgres 的开源TopN 扩展可以快速获得“top-n” 查询的近似结果。该扩展将top 值具体化为JSON 数据类型。TopN 可以增量更新这些top 值,或者在不同的时间间隔内按需合并它们。
- TopN 扩展
- https://github.com/citusdata/postgresql-topn
基本操作
在查看TopN 的实际示例之前,让我们看看它的一些原始操作是如何工作的。首先topn_add 更新一个JSON 对象,其中包含一个key 被看到的次数:
select topn_add('{}', 'a'); -- => {"a": 1} -- record the sighting of another "a" select topn_add(topn_add('{}', 'a'), 'a'); -- => {"a": 2}该扩展还提供聚合以扫描多个值:
-- for normal_rand create extension tablefunc; -- count values from a normal distribution SELECT topn_add_agg(floor(abs(i))::text) FROM normal_rand(1000, 5, 0.7) i; -- => {"2": 1, "3": 74, "4": 420, "5": 425, "6": 77, "7": 3}如果distinct 值的数量超过阈值,则聚合会丢弃那些最不常见的信息。
这可以控制空间使用。阈值可以由topn.number_of_counters GUC 控制。它的默认值为1000。
现实例子
现在来看一个更现实的例子,说明TopN 在实践中是如何工作的。让我们提取2000 年的亚马逊产品评论,并使用TopN 快速查询。首先下载数据集:
curl -L https://examples.citusdata.com/customer_reviews_2000.csv.gz | \ gunzip > reviews.csv接下来,将其摄取到分布式表中:
CREATE TABLE customer_reviews ( customer_id TEXT, review_date DATE, review_rating INTEGER, review_votes INTEGER, review_helpful_votes INTEGER, product_id CHAR(10), product_title TEXT, product_sales_rank BIGINT, product_group TEXT, product_category TEXT, product_subcategory TEXT, similar_product_ids CHAR(10)[] ); SELECT create_distributed_table('customer_reviews', 'product_id'); \COPY customer_reviews FROM 'reviews.csv' WITH CSV接下来我们将添加扩展,创建一个目标表来存储TopN 生成的json 数据,并应用我们之前看到的topn_add_agg 函数。
-- run below command from coordinator, it will be propagated to the worker nodes as well CREATE EXTENSION topn; -- a table to materialize the daily aggregate CREATE TABLE reviews_by_day ( review_date date unique, agg_data jsonb ); SELECT create_reference_table('reviews_by_day'); -- materialize how many reviews each product got per day per customer INSERT INTO reviews_by_day SELECT review_date, topn_add_agg(product_id) FROM customer_reviews GROUP BY review_date;现在,我们无需在customer_reviews 上编写复杂的窗口函数,只需将TopN 应用于reviews_by_day。 例如,以下查询查找前五天中每一天最常被评论的产品:
SELECT review_date, (topn(agg_data, 1)).* FROM reviews_by_day ORDER BY review_date LIMIT 5;┌─────────────┬────────────┬───────────┐ │ review_date │ item │ frequency │ ├─────────────┼────────────┼───────────┤ │ 2000-01-01 │ 0939173344 │ 12 │ │ 2000-01-02 │ B000050XY8 │ 11 │ │ 2000-01-03 │ 0375404368 │ 12 │ │ 2000-01-04 │ 0375408738 │ 14 │ │ 2000-01-05 │ B00000J7J4 │ 17 │ └─────────────┴────────────┴───────────┘TopN 创建的json 字段可以与topn_union 和topn_union_agg 合并。 我们可以使用后者来合并整个第一个月的数据,并列出该期间最受好评的五个产品。
SELECT (topn(topn_union_agg(agg_data), 5)).* FROM reviews_by_day WHERE review_date >= '2000-01-01' AND review_date < '2000-02-01' ORDER BY 2 DESC;┌────────────┬───────────┐ │ item │ frequency │ ├────────────┼───────────┤ │ 0375404368 │ 217 │ │ 0345417623 │ 217 │ │ 0375404376 │ 217 │ │ 0375408738 │ 217 │ │ 043936213X │ 204 │ └────────────┴───────────┘有关更多详细信息和示例,请参阅TopN readme。
百分位计算
在大量行上找到精确的百分位数可能会非常昂贵,
因为所有行都必须转移到coordinator 以进行最终排序和处理。
另一方面,找到近似值可以使用所谓的sketch 算法在worker 节点上并行完成。coordinator 节点然后将压缩摘要组合到最终结果中,而不是读取完整的行。
一种流行的百分位数sketch 算法使用称为t-digest 的压缩数据结构,可在tdigest 扩展中用于PostgreSQL。Citus 集成了对此扩展的支持。
以下是在Citus 中使用t-digest 的方法:
- 在所有
PostgreSQL节点(coordinator和所有worker)上下载并安装tdigest扩展。tdigest 扩展 github 存储库有安装说明。- https://github.com/tvondra/tdigest
- 在数据库中创建
tdigest扩展。在coordinator上运行以下命令:CREATE EXTENSION tdigest;coordinator也会将命令传播给worker。
当在查询中使用扩展中定义的任何聚合时,Citus 将重写查询以将部分tdigest 计算下推到适用的worker。
T-digest 精度可以通过传递给聚合的compression 参数来控制。
权衡是准确性与worker 和coordinator 之间共享的数据量。
有关如何在tdigest 扩展中使用聚合的完整说明,请查看官方tdigest github 存储库中的文档。
限制下推
Citus 还尽可能将限制条款下推到worker 的分片,以最大限度地减少跨网络传输的数据量。
但是,在某些情况下,带有LIMIT 子句的SELECT 查询可能需要从每个分片中获取所有行以生成准确的结果。 例如,如果查询需要按聚合列排序,则需要所有分片中该列的结果来确定最终聚合值。 由于大量的网络数据传输,这会降低LIMIT 子句的性能。 在这种情况下,如果近似值会产生有意义的结果,Citus 提供了一种用于网络高效近似LIMIT 子句的选项。
LIMIT 近似值默认禁用,可以通过设置配置参数citus.limit_clause_row_fetch_count 来启用。
在这个配置值的基础上,Citus 会限制每个任务返回的行数,用于在coordinator 上进行聚合。 由于这个limit,最终结果可能是近似的。增加此limit 将提高最终结果的准确性,同时仍提供从worker 中提取的行数的上限。
SET citus.limit_clause_row_fetch_count to 10000;分布式表的视图
Citus 支持分布式表的所有视图。有关视图的语法和功能的概述,请参阅CREATE VIEW 的PostgreSQL 文档。
- https://www.postgresql.org/docs/current/static/sql-createview.html
请注意,某些视图导致查询计划的效率低于其他视图。
有关检测和改进不良视图性能的更多信息,请参阅子查询/CTE 网络开销。
(视图在内部被视为子查询。)
- https://docs.citusdata.com/en/v11.0-beta/performance/performance_tuning.html#subquery-perf
Citus 也支持物化视图,并将它们作为本地表存储在coordinator 节点上。
连接(Join)
Citus 支持任意数量的表之间的equi-JOIN,无论它们的大小和分布方法如何。
查询计划器根据表的分布方式选择最佳连接方法和join 顺序。
它评估几个可能的join 顺序并创建一个join 计划,该计划需要通过网络传输最少的数据。
共置连接
当两个表共置时,它们可以在它们的公共分布列上有效地join。co-located join(共置连接) 是join 两个大型分布式表的最有效方式。
- https://docs.citusdata.com/en/v11.0-beta/sharding/data_modeling.html#colocation
注意
确保表分布到相同数量的分片中,并且每个表的分布列具有完全匹配的类型。尝试加入类型略有不同的列(例如 `int` 和 `bigint`)可能会导致问题。
引用表连接
引用表可以用作“维度”表,
以有效地与大型“事实”表连接。因为引用表在所有worker 上完全复制,
所以reference join 可以分解为每个worker 上的本地连接并并行执行。reference join 就像一个更灵活的co-located join 版本,
因为引用表没有分布在任何特定的列上,并且可以自由地join 到它们的任何列上。
- https://docs.citusdata.com/en/v11.0-beta/develop/reference_ddl.html#reference-tables
引用表也可以与coordinator 节点本地的表连接。
重新分区连接
在某些情况下,您可能需要在除分布列之外的列上连接两个表。
对于这种情况,Citus 还允许通过动态重新分区查询的表来连接非分布key 列。
在这种情况下,要分区的表由查询优化器根据分布列、连接键和表的大小来确定。
使用重新分区的表,可以确保只有相关的分片对相互连接,从而大大减少了通过网络传输的数据量。
通常,co-located join 比repartition join 更有效,因为repartition join 需要对数据进行混洗。
因此,您应该尽可能通过common join 键来分布表。
更多
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)