全链路压测(10):测试要做的准备工作_在线工具
前言
前面的几篇文章介绍了全链路压测准备阶段的很多事项,包括核心链路梳理、构建压测模型、容量评估和容量规划,大多都是研发和运维同学负责的事情。
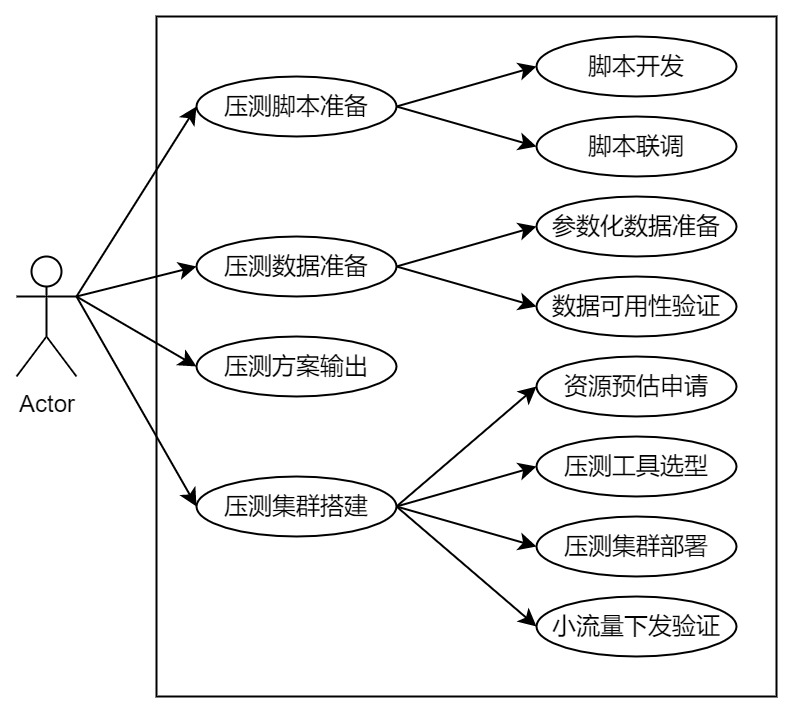
那么全链路压测在准备阶段,测试同学要做哪些事情呢?以我个人的实践经验来说,全链路压测在准备阶段,测试同学要做的事情主要有如下几点。
环境准备
一般来说,需要准备如下三套环境。环境准备阶段,大体的工作事项和分工如下:
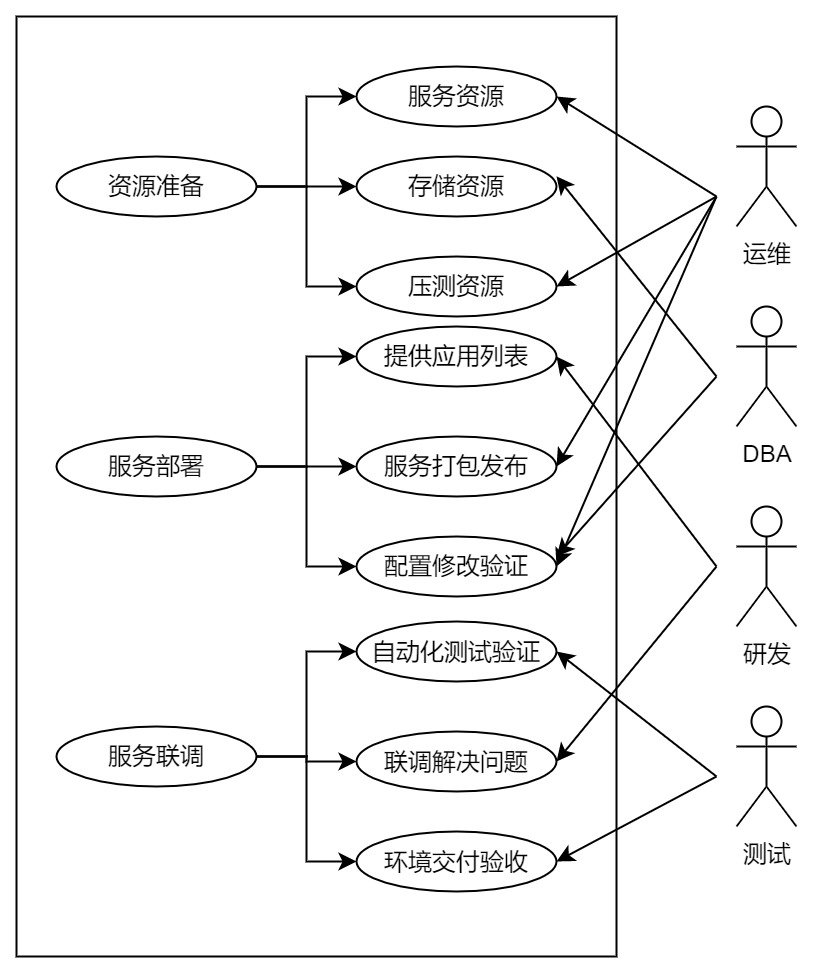
功能验证环境
功能验证环境即用来验证技术组件本身的功能正确性和接入性能损耗的环境,有独立的随时可用的环境最好。
如果考虑到成本,也可以用线下性能环境来进行验证。实践经验来说,功能验证阶段,要做的事情核心有如下几点:
- 能否快速接入;
- 压测标记是否完整的透传到了数据库表;
- 数据落库或者读库的路由逻辑是否正确;
- 下游或外部调用是否都被mock挡板过滤;
- 采用自动化的方式快速验证接口链路是否正常;
- 梳理的业务场景和测试场景是否都匹配了接入的业务范围等;
- 接入前后对业务应用以及中间件的性能损耗是否在可接受范围内;
线下性能环境
如果未经基础的测试就直接在生产环境开展全链路压测,风险和问题排查成本都是很高的。
线下性能测试环境的作用如下:
- 满足日常的版本迭代和技术优化性能验证需要;
- 生产压测前的单机单接口和单机混合链路压测验证;
- 为生产压测集群的资源扩容提供容量评估的参考依据;
生产压测集群
因为全链路压测都是在生产环境进行,压测的目的也是为了满足未来某个时期业务活动的需要,因此需要提前评估准备资源。
这里的资源指的是扩容的资源,而非单独重新搭建环境的资源。一般需要准备的资源如下:
- 带宽资源;
- CDN资源;
- 应用资源;
- 缓存资源;
- M Q资源;
- 短信资源;
- D B资源;
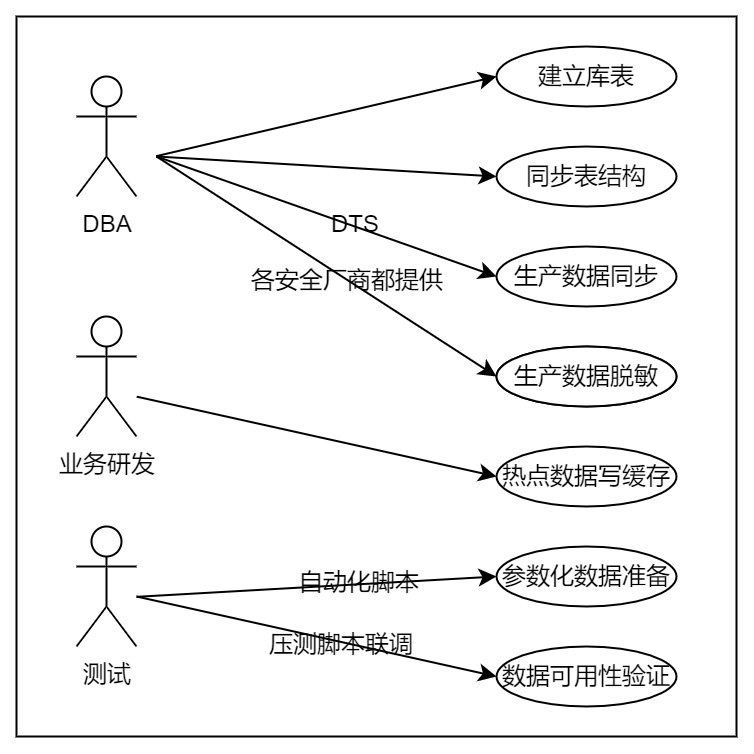
数据准备
全链路压测过程中,涉及的数据以及职责分工如下:
铺底数据
铺底数据可以简单理解为冷数据,因为SQL执行过程中,空表和大表对性能的影响还是很大的。
准备铺底数据,还要根据具体的数据隔离技术实现方案来看,分为如下2方面:
- 正式表:如果数据隔离方案采用的是读写业务表,那无须准备铺底数据。但压测产生的数据需要通过特殊字段来做标识处理,避免对业务造成影响。
- 影子表:如果采用的是影子表方案,常见的做法就是将涉及到的库表数据按需按量同步到影子表并进行脱敏。
- 影子库:影子库的数据铺底数据准备方案和影子表类似,但要考虑的一点是:因为影子库是正式库是在同一个数据库实例上,需要更多的硬件资源支撑,以及在参数配置上(如活跃连接数)需要进行一定调整。
热点数据
为了避免压测时瞬间的大流量对服务的冲击,需要提前将这些热点数据预热到缓存中。最典型的热点数据莫过于用户的登录态token了,其他还有类似秒杀活动的库存数据、商品信息数据以及优惠券等数据。
当然,热点数据的预热,需要根据具体的业务来制定预热方案,而非单纯的照着做。
参数化数据
参数化数据指的是压测过程中脚本中需要引用到的数据。以电商业务来说,常见的有用户id,商品id,订单id。
准备参数化数据的过程中,需要注意如下几点:
- 数据的幂等性(是否可重复使用);
- 数据的关联性(是否需要前置动作来更新状态);
- 数据的有效性(数据需要在使用阶段内一直生效);
- 数据的唯一性(数据在逻辑处理中仅且只有某些场景才可用);
数据可用性验证
做完了上述的几点数据准备工作,最后要做的就是对数据可用性进行验证,看看它是否如预期满足工作需要。
脚本准备
脚本开发
脚本准备实际上是个很复杂的事情,因为要考虑到具体的业务场景和压测链路。
我在实践中的做法,一般遵循如下的过程步骤:
1、梳理核心链路(得到被测应用和涉及到的接口);
2、梳理流量模型(便于压测过程中性能指标监控及流量模型配置);
3、划分脚本类型;
- 准备测试数据的脚本(某些场景用到的数据需要通过前置动作才能产生);
- 单机单接口压测脚本(性能环境快速验证接口维度的性能表现,快速发现性能瓶颈);
- 单机混合链路压测脚本(性能环境快速验证应用维度的性能表现,调整流量配比,便于容量评估);
- 生产环境全链路压测脚本(生产环境压测专用的压测脚本);
- 梯度增加脚本(验证生产环境的性能,发现性能瓶颈和拐点);
- 稳定性验证脚本(验证生产服务集群在长时间高负载情况下的稳定性);
- 数据状态恢复脚本(特殊业务场景下某些数据只能用一次,可以理解为一种数据回滚策略);
- 稳定性预案验证脚本(验证限流、熔断、降级等稳定性预案是否生效);
脚本联调
脚本开发完成,接下来就是联调工作。
联调阶段,除了要考虑环境因素,重点是验证数据模型和流量模型是否匹配的问题。
压测方案
编写压测方案的目的:同步信息,打平信息差,保持整体的压测节奏一致,为下一阶段工作做铺垫。
- 背景和目的(通用内容);
- 业务和技术指标(统一目标,即使有临时变更也能快速调整);
- 涉及范围和链路(更细化的内容,需要和涉及的各团队一一对齐);
- 压测实施里程碑(生产压测需要多轮,每轮次的目标和要做的事情);
- 压测任务及进度(整体的压测任务拆分以及当前进度,提前评估风险);
- 压测模型和策略(类似功能测试过程中的case评审,查漏补缺的过程);
上一个:Nacos服务发现基础应用
下一个:Halo 开源项目学习注册与登录